È uscito Raptor, un ambiente operativo grafico per Oracle, scritto in Java.
Viene distribuito in versione Windows "full", ovvero con la virtual machine java e JDK completo, mentre per gli altri sistemi operativi bisogna scaricarsi JDK 1.5.
Non ho trovato il JDK per Mac OS X, quindi mi sono dovuto accontentare della versione per Windows; in compenso mi sono collegato a Oracle 10gR1 su Mac :-)
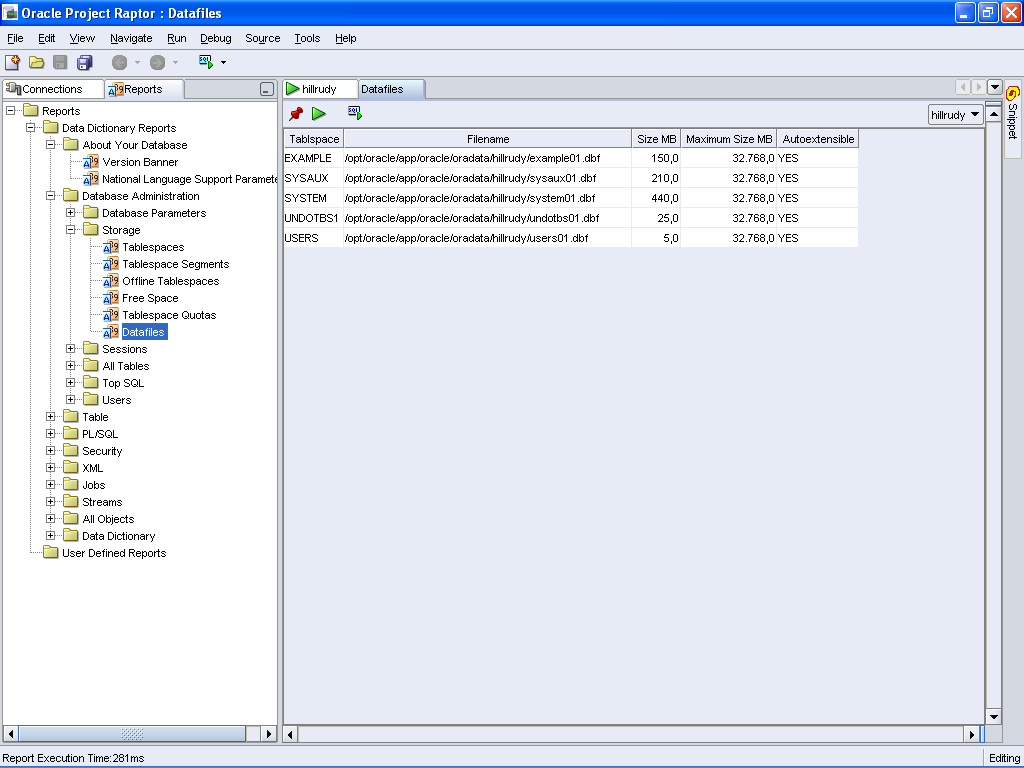
Ecco la finestra dei report con i datafile sul Mac:
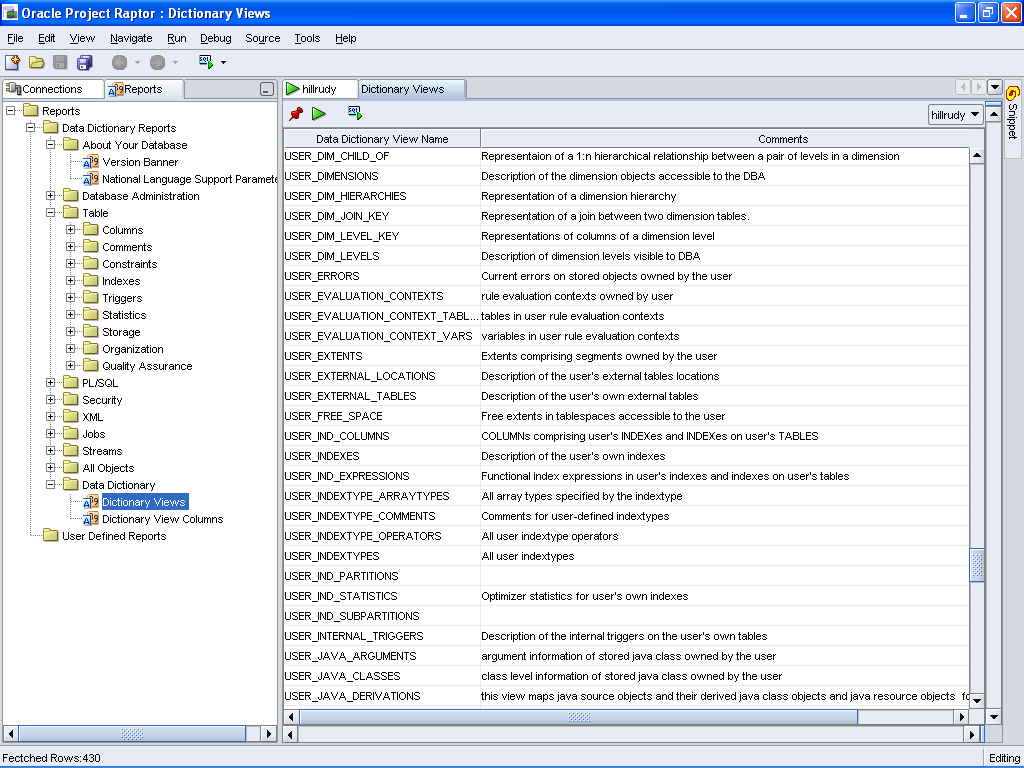
Il data dictionary con tutti i commenti originali:
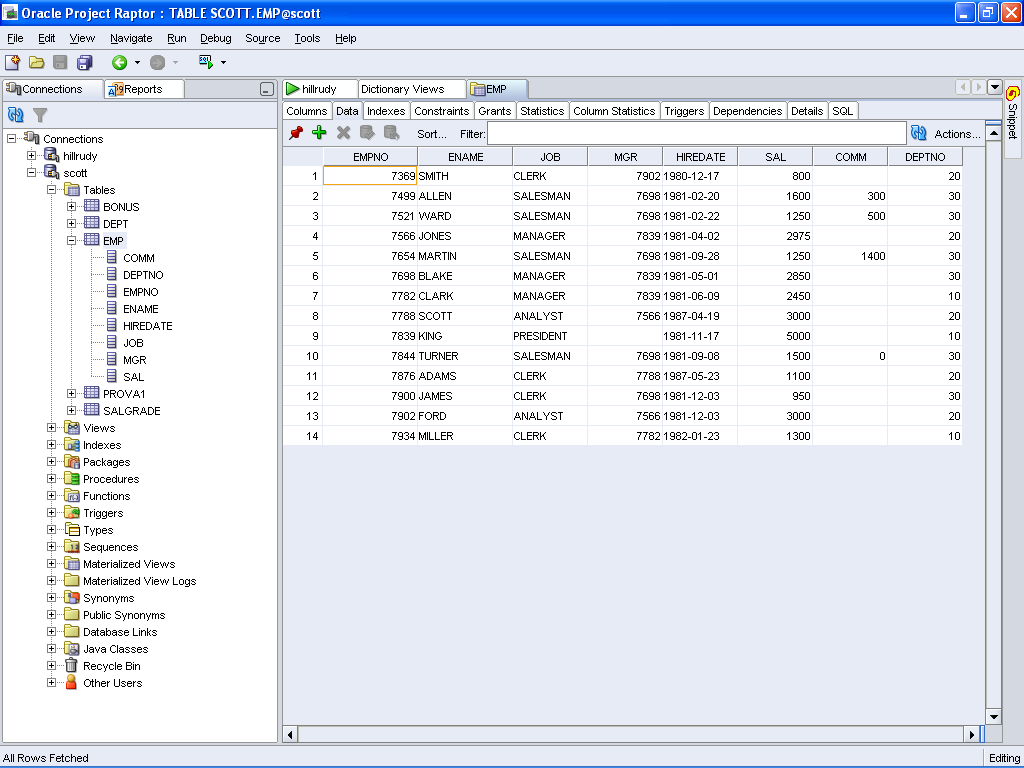
La gestione delle tabelle, editing compreso:
L'editor SQL:

È necessario dire che Raptor è gratuito e liberamente scaricabile da OTN? Beh, sì, viste le premesse e visto che intacca un mercato già consolidato come quello degli editor SQL. Oracle continua sulla doppia strada di introdurre innovazione tecnologica (più o meno guidata dal marketing) e di fornire strumenti e accessori di alto e altissimo livello a titolo gratuito per migliorare l'utilizzo dei suoi prodotti.
Ancora complimenti alla Oracle. Non si potrebbe sperare di più nemmeno dal fronte open-source.