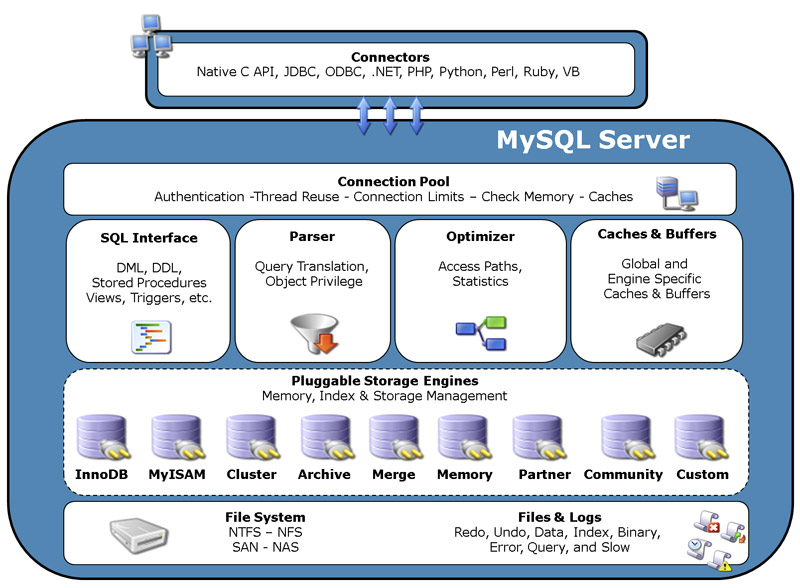
 Alcune indiscrezioni sull'uscita del filesystem ZFS nella prossima versione di Mac OS X mi hanno spinto a interessarmi, ancora una volta, a Opensolaris, aiutato anche da qualche suggerimento di tuning di Oracle dell'ultimo esame sostenuto.
Alcune indiscrezioni sull'uscita del filesystem ZFS nella prossima versione di Mac OS X mi hanno spinto a interessarmi, ancora una volta, a Opensolaris, aiutato anche da qualche suggerimento di tuning di Oracle dell'ultimo esame sostenuto.Solaris ha una caratteristica unica, ovvero la ISM (Intimate Shared Memory), che permette ai processi di condividere l'area di memoria che contiene la mappatura da indirizzi di memoria virtuali a indirizzi reali. Beh Solaris ha anche ZFS! Supporta inoltre le CPU Intel a 32 e 64 bit, oltre ai RISC di casa Sun.
Bene, ora trovo un server adeguato e poi sotto con le installazioni. Mi sembrerà di ritornare ai laboratori dell'università, ma allora utilizzavo software di calcolo per astrofisica sulle Sparcstation 4 :-)






{kind=link}